serviceWorker 方案 - js增量更新算法研究
调研背景
根据之前 serviceWorker 的调研,当服务端文件更新后,serviceWorker 会做对比,并请求这些新的文件。所有发生变化的文件都会被更新。现在 new-mini 内嵌页面,js 都被压缩成了一个文件。这样每次很小的文件改动,都会导致客户端需要下载整个js文件,这样会造成流量的浪费,同时也对服务器造成过大的流量压力。为此我们需要减少更新文件的体积,来更好的完成 serviceWorker 的架构。
js 增量更新算法
利用增量更新算法,我们大大的降低每次文件变动后传输的大小。这里调研了4中常见的js 增量更新算法:
基于chunk的增量更新算法
首先将旧的文件分成n块并并编号
然后在新文件上进行,滚动查找。如果找到匹配的则记录块号,如果没找到则块往前移动 1 个字符,并把上个字符压入新数据块,然后扫描下一块,最终得到一个新数据和数据块号的组合的增量文件(这一步可以用上线 JavaScript 时用的打包工具或者请求 JavaScript 服务器程序实时计算出来)。
最终得到的增量文件如下所示:
1, data1, 2, 3, data2, 4, 5, 6
进一步合并顺序快得到:
[1, 1], data1, [2, 2], data2, [4, 4]
客户端根据旧文件的 chunk 数据和增量更新数据,我们可以得出新版本数据由如下数据组成:
chunk0+data1+chunk1+chunk2+data2+chunk3+chunk4+chunk5
例如以 s = ‘‘1345678abcdefghijklmnopq’ 修改为 a = ‘‘13456f78abcd2efghijklmnopq’为例, 设块长度为4 则, 源文件分成:
通过滚动查找,得到新文件
最终增量文件表示如下数组: [“a=‘1”,2,”f”,3,”cd2ef”,5,6,7]。 进一步合并顺序块,可用一个js数组表示为: [“a=‘1”,[2,1],“f”,[3,1],“cd2ef”,[5,3]。
在 serviceWorker 客户端这边,调用如下函数,进行文件更新:
|
|
该方法存在的问题为:增量更新的精确度依赖于chunk的大小,在实际使用中总是会有不少代码需要冗余下载。
Myer’s diff algorithm
Myer’s diff algorithm 首次出是在1986年一篇论文中“An O(ND) Difference Algorithm and Its Variations”, 在文中实现上介绍了两种此diff算法 的实现。两种实现的核心思想是一致的,只是在具体的实现过程中,为进一步提升算法的性能及空间利用率,采取了不一致的迭代方式。
算法原理比较复杂,github 上有根据该算法实现的 jsdiff 插件
简单的演示如下:
|
|
输出结果为:
客户端,采用如下函数,更新 serviceWorker 中的资源:
function mergeDiff(oldString, diffInfo){
let newString = '';
let diffInfo = JSON.parse(diffInfo);
let index = 0;
for(var i = 0; i < diffInfo.length; i++){
let info = diffInfo[i];
if(typeof info === 'number'){
newString += oldString.slice(index, index + info);
index += info;
continue;
}
if(typeof info === 'string'){
if(info[0] === '+'){
let addedString = info.slice(1, info.length);
newString += addedString;
}
if(info[0] === '-'){
let removedCount = parseInt(info.slice(1, info.length));
index += removedCount;
}
}
}
return newString;
}
该方案,实际测试结果很糟糕,对于文件很大的内容比对时间都够我睡一觉了。
基于编辑距离的比对算法
什么是编辑距离
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。编辑距离可以用在自然语言处理中,例如拼写检查可以根据一个拼错的字和其他正确的字的编辑距离,判断哪一个(或哪几个)是比较可能的字。DNA也可以视为用A、C、G和T组成的字符串,因此编辑距离也用在生物信息学中,判断二个DNA的类似程度。Unix 下的 diff 及 patch 即是利用编辑距离来进行文本编辑对比的例子。
求解算法
比如要计算cafe和coffee的编辑距离。cafe→caffe→coffe→coffee。先创建一个6×8的表(cafe长度为4,coffee长度为6,各加2):
接着,在如下位置添加数字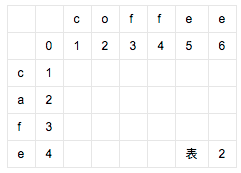
从3,3格开始,开始计算。取以下三个值的最小值:
- 如果最上方的字符等于最左方的字符,则为左上方的数字。否则为左上方的数字+1。(对于3,3来说为0)
- 左方数字+1(对于3,3格来说为2)
- 上方数字+1(对于3,3格来说为2)
因此为格3,3为0: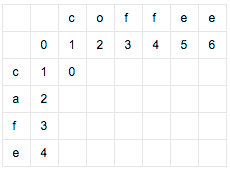
循环操作,推出下表: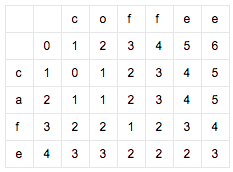
取右下角,得编辑距离为3。