随着语音技术的普及,越来越多的手机用户开始使用Siri和Cortana等语音助理软件。Amazon Echo和Google Home等语音软件同样走入了我们的日常生活。这些系统基于语音识别软件构建允许用户直接通过语音下达命令。现在,浏览器也已经支持了Web Speech API,它允许用户在web应用程序中集成语音数据。
基于现在的web应用程序,我们可以使用多种UI元素来和用户交互。使用Web Speech API,我们可以开发更加自然地小巧的web可视化界面。这样我们就能开发更丰富的web应用程序。此外,该API也可以帮助身体或认知障碍的人更好的访问web信息。
增强用户体验
Web Speeh API可以使网站和Web app不仅仅可以交谈还可以聆听。这里有一些关于猪呢个条用户体验的很好的例子。阅读更多
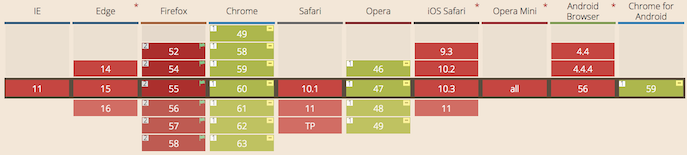
在本教程中,我们将使用API在浏览器中创建人工智能(AI)语音聊天界面。该应用将听取用户的声音并以合成语音回复。因为Web Speech API依然是实现性的,所以目前仅能支持在有限的浏览器中。本文使用的语音识别和语音合成功能目前仅基于Chromium浏览器,包括Chrome 25+和Opera 27+,而Firefox,Edge和Safari目前仅支持语音合成。

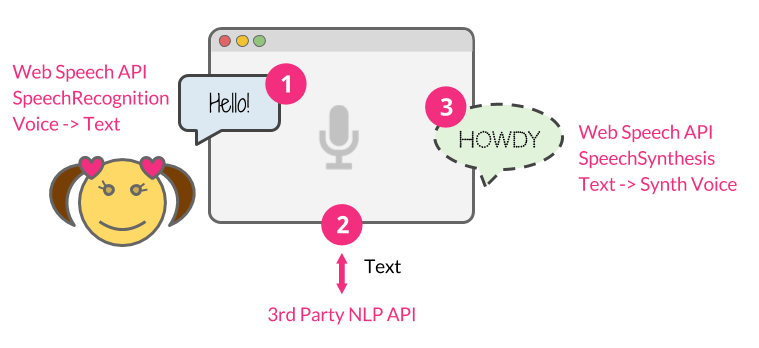
要构建该程序,我们主要采取三个步骤:
- 使用Web Speech API的SpeechRecognition接口来聆听用户的语音
- 将用户消息作为字符串文本发送给商业的自然语言处理API
- 一旦API.AI返回响应文本,我们就利用SpeechSynthesis接口返回给用户一个合成声音
本教程使用的完整的源代码在GitHub上。
先决条件
本教程依赖于Node.js,你需要对JavaScript和Node.js有一定的了解并确保您的电脑上已经安装了Noded.js。
构建你的Node.js应用
首先,让我们搭建一个Node.js的应用框架。创建你的应用目录,并设置如下的目录结构:
|
|
之后利用如下命令来初始化你的Node.js应用:
npm init -f
我们将使用Express(一个Node.js Web应用框架)来搭建本地服务。为了实现服务器和浏览器之间的双向通信,我们将使用Socket.IO。同时,我们还将使用自然语言处理工具API.AI,来构建可以人工交谈的AI聊天工具。
Socket.IO,能够让我们更方便的使用WebSocket。通过在客户端和服务端建立socket连接。当Web Speech API或API.AI 返回文本数据的时候,我们能将聊天信息在浏览器和服务器之间传递。
首先,我们创建index.js文件并实例化Express作为服务器:
|
|
下一步,我们将Web Speech API集成到前端代码。
利用 SpeechRecognition 接口接收语音
Web Speech API具有名为SpeechRecognition的接口,用来从麦克风中获取用户们的讲话并了解他们在说什么。
创建用户界面
该程序的UI界面很简单,仅有一个按钮来触发语音识别。让我们创建一个index.html文件,其中包含js文件和Socket.IO,稍后我们将用它启动实时通讯:
|
|
然后,在页面中加入按钮接口:
|
|
要想查看按钮的样式,你何以查看源代码中的style.css文件。
使用JavaScript捕获语音
在script.js中,创建SpeechRecognition实例来识别语音:
|
|
我们使用了带有前缀和不带的两个对象做判断,因为Chrome当前支持带有前缀的API。
同时,我们在本教程中使用了一些ES6语法,包括const,箭头函数等等,他们都可以在支持语音接口的浏览器中使用。
你可以设置各种属性,来自定义语音识别:
|
|
之后,监听button UI的DOM节点的点击事件来启动语音识别:
|
|
一旦语音开始,我们就调用result事件,来获取语音文本:
|
|
这将返回一个包含结果的SpeechRecognitionResultList兑现,你可以在数组中检索文字信息。接下来我们使用Socket.IO来传递数据额给我们的服务器。
Socket.IO做实时通讯
Socket.IO是一个做实时通讯web应用的库。他可以实现web客户端和服务端之间的双向通讯。我们将使用它将语音结果传递给Node.js,将相应信息传回浏览器。
你也许会有疑虑为什么我们不使用简单的HTTP协议或者AJAX。你可以发送POST请求来传奇数据。但是我们通过Socket.IO来创建webscoket,是因为这是最好的实现双向通讯的解决方案。特别是服务器向浏览器发送数据,如果采用AJAX来实现我们就不得不再用轮训的方式:
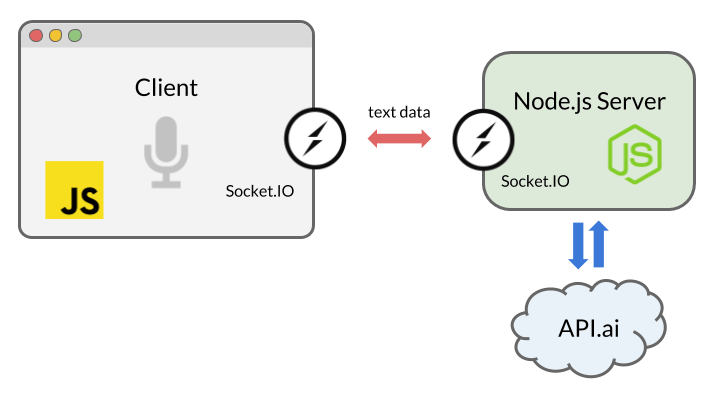
在script.js中实例化Socket.IO:
|
|
然后将下面这段代码加入到监听reuslt事件的回调函数中:
|
|
我们回到Node.js代码中,来接受这些文本并使用API来回复用户的消息。
从AI中获取回复
许多平台提供的服务可以将带有自然语言处理的AI系统结合到项目中,包括IBM的Watson,微软的LUIS和Wit.ai。为了快速构建一个会话接口,我们使用API.AI。因为它提供了免费的开发者帐户,并允许我们使用其Web界面和Node.js库快速设置一个小型的系统。
设置API.AI
首先创建一个账户和代理。更多内容可以参考入门指南中的第一步。
然后,创建entities和intents。点击左侧菜单中的”Small Talk”,然后切换开关即可开启服务。
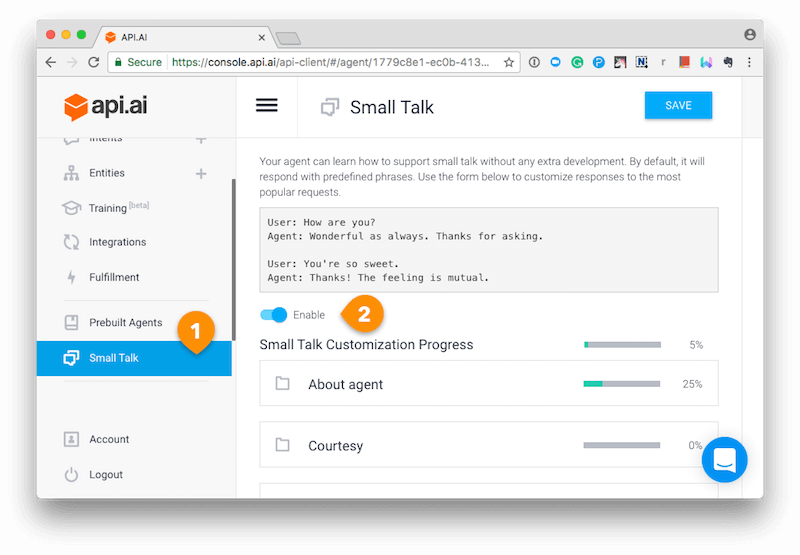
根据你的喜好,自定义API.AI接口的代理。
使用API.AI的Node.js SDK
我们利用Node.js SDK来链接Node.js应用和API.AI。回到你的index.js文件中,利用你的access token来初始化API.AI:
|
|
如果您只想在本地运行代码,可以在此处对API密钥进行编码。这里有多种方式来设置环境变量,我通常使用设置 .env 文件来包含变量信息。在GitHub源码中,我将包含凭证的信息文件添加到了.gitignroe中,你可以查看 .env-test 文件来查看他是如何设置的。
现在我么能使用服务端的Socket.IO来获取浏览器的结果。
一旦接收到消息,我们就用API.AI的API来检索并回复用户信息:
|
|
当API.AI返回结果时,使用Socket.IO socket.emit()将其发送回浏览器。
利用SpeechSynthesis接口来合成语音
然我们再次回到script.js中,完成我们的应用!
创建一个语音合成器,这次我们使用SpeechSynthesis接口。该函数将接受字符串作为参数,并使浏览器能够说出文本:
|
|
该函数中,我们首先创建了一个API入口对象,window.speechSynthesis。这次我们没有在使用前缀,该API的支持度更高,许多浏览器已经移除了该前缀。
然后,我们创建一个SpeechSynthesisUtterance实例,并设置要合成语音的文本。你也可以设置其他属性,例如voice类型和操作系统支持的语音类型。
最后,我们使用SpeechSynthesis.speak()来是浏览器说话。现在,再次从Socket.IO获取服务器的响应。一旦接收到消息,请调用该功能。
|
|
至此我们完成了全部功能,你可以试试:
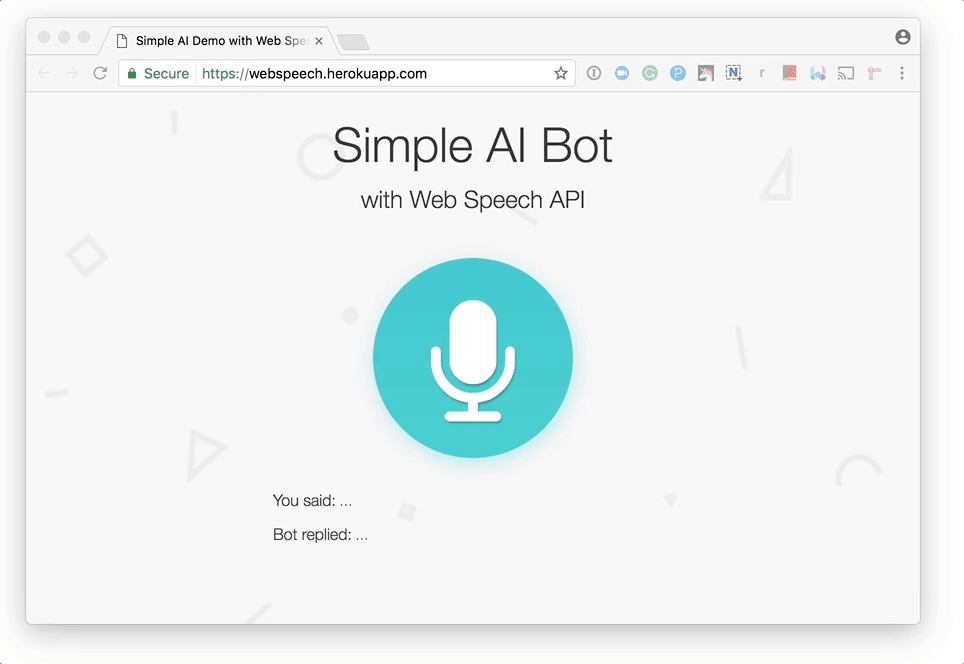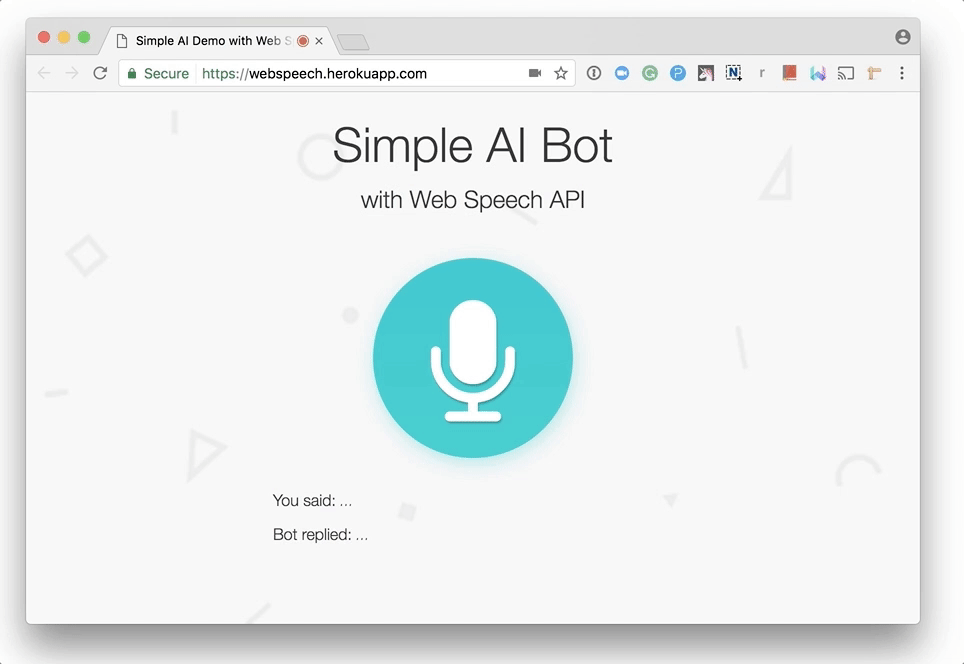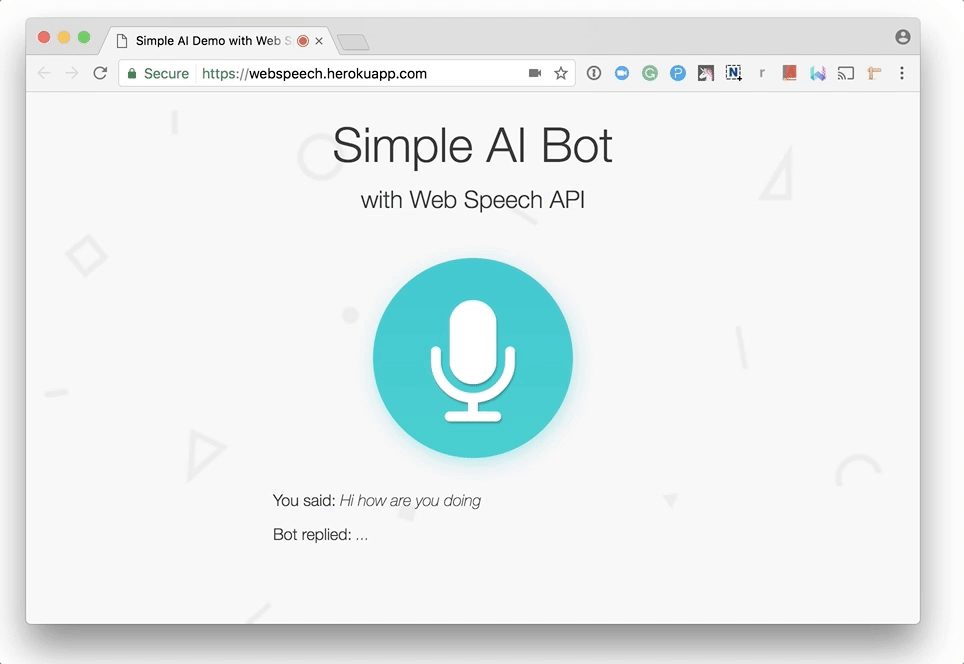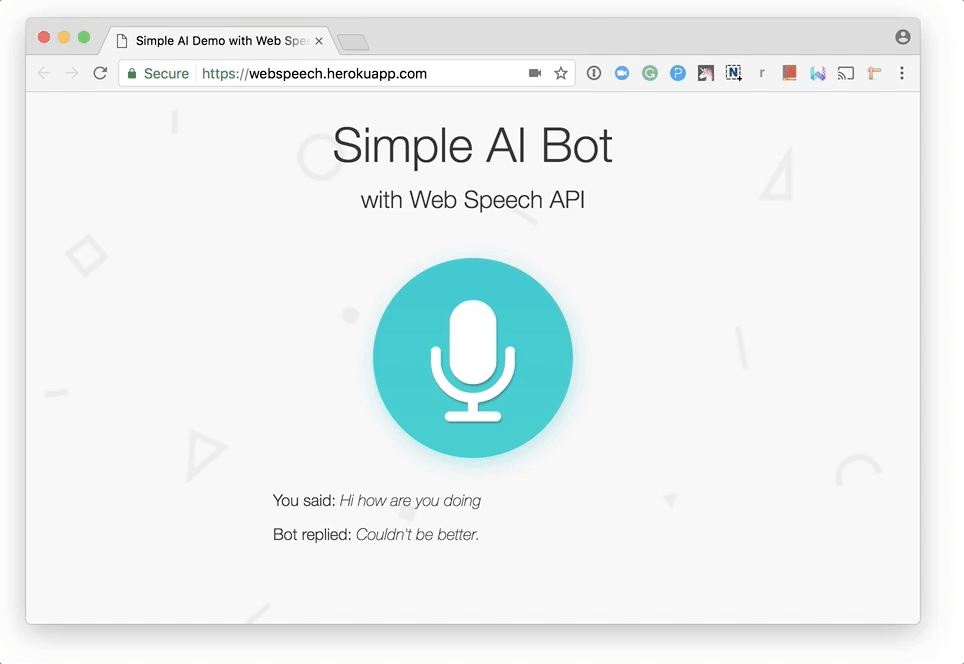
请注意,浏览器在首次的时候会询问你是否使用麦克风。像其他Web API(如Geolocation API和Notification API)一样,除非你授予它,否则浏览器将永远不会访问您的敏感信息,因此你的声音不会在不知情的情况下被秘密记录。
API.AI是可配置和可训练的。阅读API.AI文档,使其更加智能。
参考
本教程仅涵盖了API的核心功能,但该API实际上是非常灵活和可自定义的。您可以改变识别语言,合成语音,包括口音(如美国或英国英语),语音音调和语速。你可以在这里了解有关API的更多信息:
- Web Speech API Mozilla Developer Network
- Web Speech API Specification W3C
- Web Speech API: Speech Synthesis (Microsoft Edge documentation) Microsoft
自然语言处理工具你可以参考如下: